Effortless AWS Serverless Integration Testing: Setup local testing environment
set breakpoints and step-through your code in the cloud
Staff Engineer @ Calo Inc.
"Remocal" (remote-local) is making waves on the internet as the testing landscape shifts towards the cloud. You no longer have a single entity that holds all of your system running locally in a container that you can test, rather now you have tens or even hundreds of cloud-distributed components.
A lot of us at Calo come from a non-cloud background, and when it comes to testing it can be a difficult concept to wrap your head around when thinking of testing your lambdas or architecture, as your code is split up into multiple parts and are connected between components that don't live in your machine. We're all used to setting breakpoints in our IDE and stepping through the path of execution. Solutions such as LocalStack & serverless-offline do exist, but they're very cumbersome to set up and yet another tool that the developer needs to learn, configure, and debug if anything goes wrong, and you're going to be testing against mocks and not the actual services. The only thing that we should accept to be in our machine is the lambda code as it's just a javascript file that is authored by us the devs, otherwise, any AWS service should not be mocked or emulated locally and we should test against it remotely.
The goal was set to answer the question
How can we make testing serverless applications in the cloud feel as familiar and effortless as possible for developers? Additionally, how can we boost their confidence with every code change?
Types of integration tests
Before diving deep into technicalities, at Calo, we mainly focus on integration tests as they give the most & quickest value for us. We categorize integration tests into two sets of categories, infrastructure & business logic tests.
| Infrastructure (Components) | Business Logic (Implementation Details) |
| Covers the configuration of your AWS components | Covers the AWS lambda code a.k.a business logic |

Infrastructure testing
These type of tests checks against the configurations of your components such as the SQS queue redrive policy, whether you have a DLQ setup for the lambda, or even that the lambda is listening to an SQS queue that has a policy that allows Event Bridge that has a rule that filters on a certain pattern. The sky is the limit when it comes to infrastructure testing. You will have to make your own choices on what is important to test against, and what doesn't add any value.
Infrastructure testing is not unique, in the sense that you will notice that a lot of your architecture has the same patterns i.e (API Gateway -> Lambda -> Dynamodb) . This means this kind of testing logic is going to be repeated. Duplication is fine in this case, what you can do is abstract these tests so that they can easily be used by multiple developers in different projects. We make use of the AWS SDK to query and assert against the query results for our tests.
Business Logic
Business logic (implementation details) integration tests are the most straightforward tests. These tests cover the code that the developer is packaging up and deploying in lambda functions. Most importantly here is where we make whatever code we wrote that executes business logic works as it should. Both happy path and edge cases such as an item not found in the database and what kind of response we send back to the client. Also, being in an event-driven architecture and using services such as SQS, Event Bridge, etc. comes with a retry mechanism. We write code that is being shipped to the AWS Lambda to handle such cases, and we should test against it as well. Things like partial failure and the requirement for it to work is to return an object that has a key that holds a list of SQS message IDs that have failed and need to be retried. The retry logic is part of the business logic and is not only technical, yes it's technology-specific, but these are the conditions that the business requirements have set and should be tested against.
Preparing the project
Setting up the project to enable integration tests is straightforward, an introduction of a couple of plugins does the job. We highly recommend automating it for your developers to remove the extra steps that are required to set up the project for testing. It's very important to abstract this kind of work away from the developer because our goal is to make writing tests as seamless as possible without any overhead, making it easier to break the barrier.
Temporary (ephemeral) environment
Having one shared environment such as dev or staging in the long run will create more problems than it solves. Yes, it makes sense for a small team of developers that works independently on features, but as you scale in team size and also in work and changes being introduced, things will start to clash. This was a huge problem for us as the business and teams started to scale. A lot of WIP code was being pushed into one single branch to be tested, code started to be overwritten, and testing things was a huge hassle. Not only that but cleaning up after tests is not an easy task. Most of your tests will have "arrange" code, such as creating a user in the database or even cognito before executing a test case, making sure that test data is not left behind or even temporary resources created during tests is impossible to achieve.
Not only is the clean-up process difficult, but also testing against an environment that replicates what is in production is integral for us and with a shared environment that is not possible. This means the code that I should test against should exclude any other changes that are not in production yet, except for the one I am writing. Again the goal here is to be able to replicate exactly what will be deployed to production and test against how will it react in a production-like environment.
This is why we need temporary environments or the fancy term ephemeral environments. In AWS terms, just another CloudFormation stack. As a best practice, doesn't matter if your organization has one single AWS account or multiple for the different environments (dev & prod) your CFN stacks and resources should have the stage as a suffix for example calo-user-service-[[prod]]. This practice can enable us to deploy and destroy stacks of the same application by defining a new "stage".
# deploy a new stack with a stage name 'abc'
npx sls deploy --stage abc
Temporary environment caveat
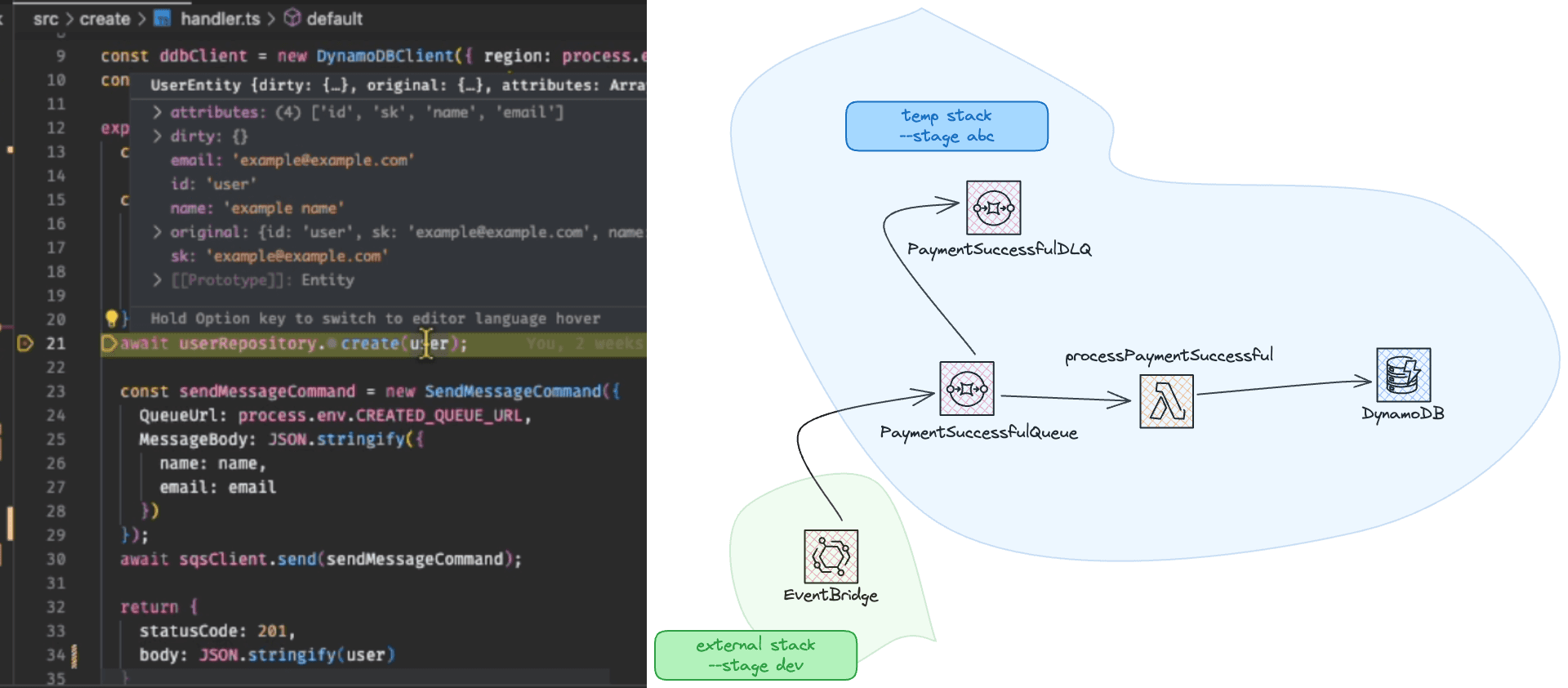
In a microservices type of architecture, your service may depend on external service resources. The simplest example is the system-wide event bridge that is shared between the different services. The event bridge resource could have been created in a different stack that you as a service don't own and don't have control over. However, we have seen other developers opting to create their Event Bridge just to isolate the environment, even more, to avoid publishing events to the event bridge that is being listened to by other stacks or having unwanted events being pushed to the temporary testing stack. In this article, we'll opt to keep the same event bridge bus instance that is owned by another service.

The below CFN template is a definition of multiple resources. An Event Bridge rule that filters events from the bus event-bus-${sls:stage}-name (which is external) and pushes them to the SQS queue PaymentSuccessfulQueue that the service we're testing against owns it as a resource.
Resources:
PaymentSuccessfulQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: ${sls:service}-${sls:stage}-PaymentSuccessful
RedrivePolicy:
deadLetterTargetArn:
Fn::GetAtt:
- PaymentSuccessfulQueue
- Arn
maxReceiveCount: 5
PaymentSuccessfulDLQ:
Type: AWS::SQS::Queue
PaymentSuccessfulSQSEventRule:
Type: AWS::Events::Rule
Properties:
Description: 'PaymentSuccessful SQS EventRule'
EventBusName:
Fn::ImportValue: event-bus-${sls:stage}-name
EventPattern:
source:
- calo.payments
detail-type:
- PaymentSuccessful
Targets:
- Arn:
Fn::GetAtt:
- PaymentSuccessfulQueue
- Arn
Id: 'SQSqueue'
In the above serverless framework command npx sls deploy --stage abc we decided that the temporary environment stage will be called abc, which means all the references to the ${sls:stage} variable will be replaced with abc. This creates a problem because the resource event-bus-[[abc]]-name doesn't exist, rather event-bus-[[dev]]-name or event-bus-[[prod]]-name does.
To get over this a simple serverless framework plugin can be written that could help us overcome this issue. The plugin should do one thing which is to expose a variable that will hold the value that we need, which is dev if it's going to be a deployment that is non-prod, and prod if it's a production deployment.
'use strict';
class LocalPlugin {
constructor(serverless) {
this.configurationVariablesSources = {
local: {
async resolve({ resolveVariable, address }) {
switch (address) {
case 'stage':
return LocalPlugin.resolveStage(await resolveVariable('sls:stage'))
}
throw new Error('Unsupported variable')
}
}
};
}
static resolveStage(stage) {
if (!['prod', 'dev'].includes(stage)) {
stage = 'dev'
}
return {
value: stage
};
}
}
module.exports = LocalPlugin;
In your serverless.ts you will need to reference the plugin to enable it
module.exports = {
service: 'remocal-testing',
plugins: [
'./plugins/local.js' // local path to plugin JS file
],
...
}
With this plugin, we now have a new variable that is accessible in the project ${local:stage} that we can go ahead and replace any reference to ${sls:stage} that is of an external resource with it, resulting in the following change to the CFN template
Resources:
....
....
PaymentSuccessfulSQSEventRule:
Type: AWS::Events::Rule
Properties:
Description: 'PaymentSuccessful SQS EventRule'
EventBusName:
Fn::ImportValue: event-bus-${local:stage}-name # <<< !!
EventPattern:
source:
- calo.payments
detail-type:
- PaymentSuccessful
Targets:
- Arn:
Fn::GetAtt:
- PaymentSuccessfulQueue
- Arn
Id: 'SQSqueue'
Configuring our local dev environment
The temporary environment is ready and has been deployed, all we have left to do is execute our integration tests. However, there are a couple of steps that we need to go through to prepare our local development environment for testing.
Accessing Environment Variables Locally
Most of the lambda code we write, if not all, doesn't just get the request from the event and return a response, it also makes calls to other AWS services such as Secrets Manager or DynamoDB. In such cases, we need the values to make the actual calls to these services to verify our test cases, usually, these values are set as environment variables on the lambda, such as the table name.
processPaymentSuccessful:
handler: src/paymentSuccessful/handler.default
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:GetItem
- dynamodb:PutItem
Resource:
- Fn::GetAtt:
- MyDynamodbTable
- Arn
environment:
MY_DYNAMO_DB_TABLE_NAME:
Ref: MyDynamodbTable
events:
- sqs:
arn:
Fn::GetAtt:
- PaymentSuccessfulQueue
- Arn
batchSize: 10
functionResponseType: ReportBatchItemFailures
const ddbClient = new DynamodbClient({ region: process.env.REGION });
export default async (event) => {
....
const updateItemCommand = new UpdateItemCommand({
TableName: process.env.MY_DYNAMO_DB_TABLE_NAME,
....
});
await ddbClient.send(updateItemCommand);
....
}
Since we're executing our lambda handler code locally, we need the environment variables as they are defined when our code is in the cloud. We can make use of another Serverless Framework plugin serverless-export-env that exports the environment variables that are defined on all the lambda functions in our stack.
STAGE=abc npx cross-env STAGE=${STAGE:=dev} sls export-env -s ${STAGE:=dev} --all --overwrite
The above command will go through all the lambdas that we have in the stack and create a new file locally .env that contains all the environment variable keys and their value.
# .env file content after running sls export-env command
REGION=us-east-1
MY_DYNAMO_DB_TABLE_NAME=my-dynamodb-table
....
Jest configuration
At Calo, we're currently using jest as the testing framework. Since we have our environment variables exported and available locally in the .env file, we can now inject them into the node process that is running our tests. Below is a basic configuration of a jest configuration file specifically for integration tests. There are a couple of properties that are worth pointing out...
// jest.config.integration.js
module.exports = {
....
testTimeout: 120_000, // <<< !!
setupFilesAfterEnv: ['./init-integration-tests.js'] // <<< !!
};
testTimeout - In some test cases that are testing against a "long" running workflow such as waiting for the message to fail multiple times and be pushed to a DLQ and asserting that the message did reach the DLQ an increase of the timeout is necessary. For that, we set the default timeout value for the integration tests to be long enough before timing out
setupFilesAfterEnv - For us to inject the environment variables we exported into the jest process that is running our integration test, we can define a path to a javascript file that can help us with that which will be executed before running the tests by jest. Below is a code snippet of how we can make that possible.
// ./init-integration-tests.js
import dotenv from 'dotenv';
import path from 'path';
process.env.STAGE = process.env.STAGE || 'dev';
// Load the exported environment variables
dotenv.config({
path: path.resolve(__dirname, '../../../.env')
});
VS Code Configuration
To make the developer experience more seamless, can take advantage of our IDE. If you're using VS Code you can make use of the launch configurations to run your test cases. The below code is a snippet of one of the launch configurations we make use of to run our tests. By running this configuration when one of our integration test suites is open, it will run the jest executable with the jest configuration file that we have discussed in the previous section. With this configuration, we can set breakpoints in VS Code for the lambda handler code that is being executed by the test and start stepping through and debugging.
Regardless of the IDE of your choice, maybe Webstorm, a bit of researching online you will find a similar configuration or create one that would work for you.
// .vscode/launch.json
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Integration Test - Current File",
"program": "${workspaceFolder}/node_modules/.bin/jest",
"args": [
"${fileBasenameNoExtension}",
"--config",
"${workspaceFolder}/jest.config.integration.js"
],
"windows": {
"program": "${workspaceFolder}/node_modules/jest/bin/jest",
},
"env": {
"AWS_PROFILE": "default"
},
"console": "internalConsole",
"outputCapture": "std",
"disableOptimisticBPs": true
}
]
}
With the launch file with the configuration created, we can now run our test suite using the Run & Debug feature in VS Code.

Closing
In the initial installment of this series, we delved into Calo's testing strategy for integration testing in our serverless applications. Our approach involves two vital types of integration tests—Infrastructure and Business Logic—both playing a pivotal role in instilling the confidence needed for refactoring and introducing new code to our application. It is crucial to grasp the pitfalls of attempting to replicate the cloud environment and why it is an unfavorable practice in testing serverless applications. Minimizing such emulation is key to maximizing confidence during the go-live phase. We also briefly explored setting up a "local" testing environment for running integration tests and debugging code in VS Code.
Subsequent articles will escalate the discussion, focusing on automating developer boilerplate to further empower them on their testing journey.